深入浅出堆数据结构 原理、应用与在数据处理中的关键角色
引言:为什么需要堆?
在计算机科学和软件工程领域,高效地管理和处理数据是核心挑战之一。当我们需要频繁地从一组动态数据中快速找到最大值或最小值时,传统的数组或链表往往力不从心。此时,堆(Heap) 这种特殊的数据结构便脱颖而出。它不仅是高效优先队列的实现基础,更在现代数据处理、调度系统、乃至大数据和机器学习算法中扮演着关键角色。本文将以CSDN博客技术社区的视角,结合数据处理和存储支持服务的实际应用场景,为你全面解析堆数据结构的奥秘。
第一部分:堆数据结构核心原理
1.1 堆的定义与性质
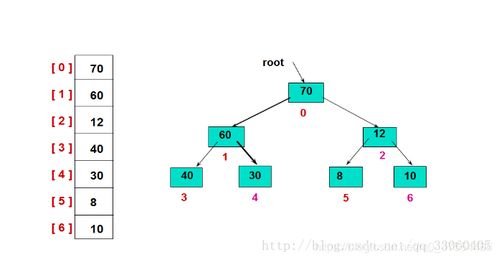
堆是一种特殊的完全二叉树,它满足以下关键性质:
- 堆序性:对于最大堆(Max-Heap),任意节点的值都大于或等于其子节点的值(根节点为最大值);对于最小堆(Min-Heap),任意节点的值都小于或等于其子节点的值(根节点为最小值)。
- 结构性:堆总是一棵完全二叉树,这意味着除了最底层,其他层都被完全填满,且节点尽可能向左对齐。
1.2 核心操作与时间复杂度
堆的核心操作及其高效性是其被广泛应用的原因:
- 插入(Insert):将新元素添加到堆的末尾,然后通过“上浮”(对于最大堆)操作调整其位置,以维持堆序性。时间复杂度为 O(log n)。
- 删除堆顶元素(Extract-Max/Min):移除并返回堆顶元素(最大值或最小值),将堆末尾元素移到堆顶,然后通过“下沉”操作进行调整。时间复杂度同样为 O(log n)。
- 查看堆顶(Peek):直接返回堆顶元素,时间复杂度为 O(1)。
- 构建堆(Heapify):将一个无序数组原地构建成堆。通过自底向上的“下沉”操作,可以在 O(n) 时间内完成,这比逐个插入的 O(n log n) 更高效。
1.3 存储方式:数组的魅力
堆虽然逻辑上是一棵树,但在物理上通常使用数组进行存储,这得益于其完全二叉树的性质。对于数组中索引为 i 的节点(通常从0开始):
- 其父节点索引为:(i-1)/2(向下取整)。
- 其左子节点索引为:2<em>i + 1。
- 其右子节点索引为:2</em>i + 2。
这种存储方式极其紧凑,无需额外的指针开销,缓存友好,是堆高效运行的物理基础。
第二部分:堆的经典应用场景
2.1 优先队列(Priority Queue)
这是堆最直接的应用。操作系统中的进程调度(如按优先级)、网络数据包管理、 Dijkstra 和 A* 等图算法中寻找最短路径,都依赖于优先队列来高效获取“下一个最优元素”。
2.2 堆排序(Heap Sort)
一种原地的、时间复杂度为 O(n log n) 的排序算法。其过程分为两步:1)将无序数组构建成最大堆;2)反复将堆顶最大元素与堆末尾元素交换并缩小堆范围,再调整堆。虽然不如快速排序或归并排序常用,但其最坏情况下的稳定 O(n log n) 性能是其优势。
2.3 求Top-K问题
在海量数据(如数亿条搜索记录)中找出前K个最大(或最小)的元素,堆是完美工具。
- 求最大K个:维护一个大小为K的最小堆。遍历数据,若当前元素比堆顶大,则替换堆顶并调整。遍历完成后,堆中的K个元素即为最大的K个。
- 求最小K个:则维护一个大小为K的最大堆。
此方法的时间复杂度为 O(n log K),空间复杂度仅为 O(K),非常适合处理无法一次性装入内存的大数据。
第三部分:堆在数据处理与存储支持服务中的实践
在构建现代数据处理和存储支持服务时,堆是工程师工具箱中的利器。
3.1 实时流数据处理
在类似Apache Kafka或Flink的流处理系统中,堆常用于实现时间窗口内的有序事件处理或聚合。例如,处理来自全球传感器的时序数据时,可能需要一个最小堆来确保事件按时间戳顺序被处理,即使它们到达的顺序是乱序的。
3.2 数据库与索引优化
一些数据库管理系统使用堆(或变种)来管理内存中的临时结果集、合并多个有序列表(如归并排序中的多路归并),或者在实现某些类型的索引时作为辅助结构。例如,在维护最近最少使用(LRU)缓存策略的变体中,也可能用到堆来高效追踪访问时间。
3.3 资源管理与调度
在云计算和容器编排平台(如Kubernetes)的调度器核心,堆是调度算法的核心数据结构。调度器需要从成千上万的待调度Pod(或任务)中,根据优先级、资源需求、亲和性等复杂规则,快速选出最合适的节点进行部署,这本质上是一个动态的优先队列问题。
3.4 监控与告警系统
在大型IT系统的监控平台中,需要实时计算各项指标(如CPU使用率、请求延迟)的百分位数(如95分位、99分位)。使用两个堆(一个最大堆保存较小的部分,一个最小堆保存较大的部分)可以动态且高效地维护数据流的中位数或任意百分位数,从而实现实时告警。
第四部分:超越二叉堆——高级堆结构
虽然二叉堆通用且高效,但在特定场景下,其合并操作(Merge)效率较低(O(n))。因此衍生出一些高级堆结构:
- 二项堆(Binomial Heap) 和 斐波那契堆(Fibonacci Heap):支持高效的合并操作,在摊销分析下,斐波那契堆的插入和降低关键字操作可达到 O(1),是某些图算法(如改进的Dijkstra算法)的理论最优选择。
- 左倾堆(Leftist Heap) 和 斜堆(Skew Heap):易于实现的“可合并堆”,常用于函数式编程语言中。
掌握堆,提升数据处理能力
堆数据结构以其简洁的定义、高效的性能和广泛的应用,成为了连接基础算法与复杂系统实现的桥梁。无论是准备技术面试,还是设计下一个高并发的数据处理服务,深入理解堆的原理和应用都至关重要。希望这篇来自CSDN博客技术视角的详解,能帮助你不仅理解堆的代码实现,更能洞察其在数据处理和存储支持服务等真实、复杂系统中的强大力量。
行动建议:尝试使用你熟悉的编程语言(如Java的PriorityQueue, Python的heapq)实现一个Top-K求解器,或模拟一个简单的任务调度器,在实践中深化对堆的理解。
最新产品